
RTO, RPO, and Reality: What CIOs Should Be Asking Before Chasing Numbers


When CIOs talk about resilience, they often mention a few acronyms: RTO, RPO, and SLA. They look good in board decks. They feel measurable. But most organizations never stop to ask the harder question: “Can our environment even support those numbers?”
The Definitions That Matter
- RTO (Recovery Time Objective) is your set objective for how long it takes at maximum to bring systems back online after an outage
- RPO (Recovery Point Objective) defines how much data loss your business can tolerate
They’re easy to quote, tough to achieve. And achieving them is rarely just about the tools; it’s about the entire architecture behind them.
According to NIST SP 800-34, both RTO and RPO depend on system interdependencies, application criticality, and restoration sequence, not on any single backup product. In practice, that means even the most advanced replication or DRaaS platform will fail to meet its targets if the business hasn’t aligned its internal systems and operations to support them.
The Hidden Variable: Your Own Infrastructure
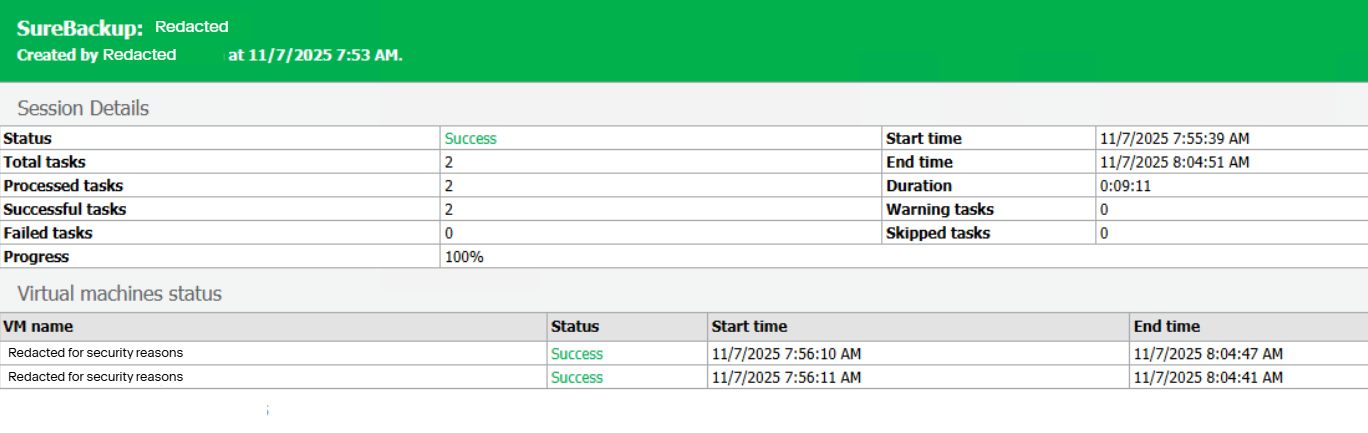
Dynascale’s most recent restore drill was completed in 9 minutes and 11 seconds beating the 20-minute RTO and a 20-minute RPO by more than half (numbers that look great on paper). But as our CIO, David Closson, often reminds clients:
“Meeting those numbers doesn’t start with our resilient infrastructure. It starts with yours.”
That’s the part many teams overlook. Replication can copy data every second, but if an application isn’t designed for rapid failover (or still depends on a monolithic database that takes 40 minutes to restart), you’ll never meet a low RTO/RPO in the real world.
Achieving “fast” recovery requires asking uncomfortable internal questions:
- Are legacy applications optimized to start cleanly on new hardware or containers?
- Are the file/object and database services loosely coupled from those that use them?
- Do we have the cross-functional buy-in (from Dev, Ops, Security, and Finance) to redesign what we can do?
For many companies, those questions expose the real constraint: not technology, but alignment.
Rethinking What “Good Enough” Looks Like
The conversation isn’t only how to hit an RTO/RPO goal, but whether that goal makes sense. For example:
- Does every workload need a 20-minute RPO, or only customer-facing systems?
- Would a 2-hour RTO still meet SLAs if the business impact is negligible?
- Could multi-region containerization and microservices make recovery irrelevant by keeping systems continuously available?
These are strategic calls, not engineering tweaks. A CIO’s job is to translate risk tolerance into technical policy, deciding where precision matters and where it doesn’t.
Gartner’s latest guidance on business continuity planning emphasizes that recovery objectives should be “tiered based on business impact rather than standardized across systems” (Gartner, 2024). That approach prevents over-engineering environments that don’t need it and focuses on investment where downtime truly costs money.
Collaboration Over Configuration
For companies of any size, from SMB to Enterprise, resilience is a cross-departmental sport.
- Developers need to containerize or refactor apps
- Design and product teams must understand dependencies
- Finance must budget for the testing cadence that keeps those numbers real
A 20-minute RTO goal without coordinated ownership across these groups is an empty metric.
At Dynascale, we run monthly restore drills (largely automated) to verify our environment, and we encourage customers to do the same (at whatever frequency their business risk demands). Every test surfaces one or two lessons about configurations, permissions, or application behavior that would never show up in a static SLA document.
From Numbers to Maturity
RTO and RPO aren’t just metrics; they’re maturity indicators.
If your recovery targets are achievable only in theory, they signal where your infrastructure (or your collaboration) needs work. As David Closson puts it:
“A 20-minute RTO means every piece of your stack, every person involved, and every process in place can support a 20-minute RTO. Otherwise, it’s just an objective.”
Before you chase another benchmark, start with an internal audit:
- Map dependencies. Know which services must come up first.
- Validate your baselines. Test your current RTO/RPO and document the gaps.
- Prioritize workloads. Not everything needs instant recovery.
- Align people. Make recovery a shared responsibility, not a single team’s burden.
- Automate wisely. Use replication, snapshots, and DRaaS to enforce consistency, but only after architecture and process are solid. Often services can be designed multi-region active-active which could provide immediate recovery to a health region.
The Takeaway
For IT leaders, resilience isn’t about matching hyperscaler metrics, it’s about setting achievable objectives that reflect the reality of your infrastructure and culture.
Every minute of RTO or RPO you shave off isn’t the result of a new product; it’s the by-product of collaboration, redesign, refactoring, and disciplined testing.
If your current SLAs sound great but feel unattainable, the next step isn’t to buy more technology. It’s to start asking better questions.
If you want to sanity-check your RTO/RPO targets, one of our engineers can walk you through a real restore drill. Just reach out to us.
Read Next



Get in touch
_ Get a tailored estimate based on your unique infrastructure needs. Understand your costs and scale with confidence.






